
CTO et co-fondateur de Primary Data, David Flynn n'est pas un inconnu pour les lecteurs du Monde Informatique puisqu'il était jusqu'en mai 2013 directeur général de la start-up Fusion-io que nous avons plusieurs fois rencontré à San José. Et le CEO de Primary Data n'est autre que Lance Smith, l'ancien COO de Fusion-io. Leur société ayant été acquise par SanDisk en juin 2014 pour un montant de 1,1 milliard de dollars, la fine équipe a rapidement rebondi en lançant Primary Data en août 2013, embarquant pour l'occasion leur conseiller scientifique de luxe, Steve Wozniak. Forte de 80 employés, la jeune pousse, installée à Los Altos, a levé 60 millions de dollars et annonce déjà 10 000 utilisateurs alors que sa solution n'est disponible que depuis quelques mois.
Alors que la virtualisation des serveurs a rendu l'informatique plus efficace et que la virtualisation du réseau commencer à faire le même travail pour les communications, le stockage reste - dans de nombreux cas - toujours lié à des plates-formes matérielles spécifiques. Des fournisseurs bien implantés comme EMC commencent certes à offrir des outils comme ViPR pour supporter différents systèmes, mais il s'agit avant tout de faciliter les migrations vers ses solutions. Primary Data se place dans une tout autre logique en séparant le contrôle des données du support du stockage grâce à une couche de virtualisation doté d'une extension vers le cloud. Une fois la phase de détection terminée et des agents (Data Hypervisor) installés sur les baies, les serveurs et les VM, toutes les capacités de stockage - du cloud aux baies flash - font partie d'un espace global peut ensuite être réparti pour répondre à des besoins de haute performance ou de haute capacité, nous a indiqué Lance Smith.
Un protocole unique, NFS, pour fédérer bloc, objet et fichier
Cet espace virtuel peut s'étendre sur les systèmes blocs, objets et fichiers, en conservant les protocoles de transport spécifiques tels que Fibre Channel, mais le traitement de toutes les données passe en mode fichiers. Au lieu d'utiliser un nouveau protocole, le logiciel de données primaire repose sur le très utilisé NFS (Network File System). Le Data Hypervisor, épaulé par un Data Director qui gère les métadonnées de tous les fichiers stockés, répond à toutes les requêtes via un espace cache (voir illustration). Les données primaires sont aujourd'hui gérées par une appliance physique pour accélérer la localisation et le transfert des fichiers mais une version cloud - une VM donc - sera disponible en milieu d'année pour répondre à plusieurs demandes de clients.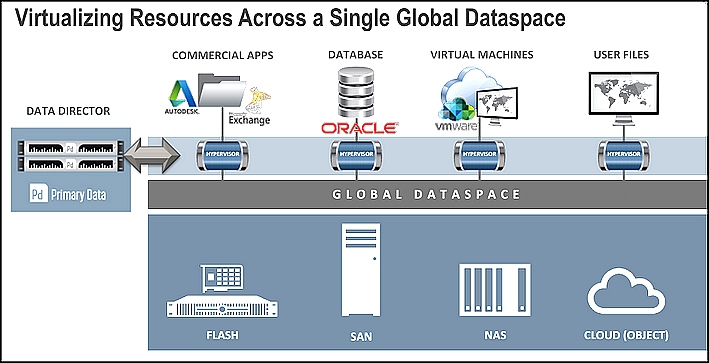
Un hyperviseur sur chaque machine assure la gestion des fichiers dans un espace globale.
« Avec la virtualisation des données, chaque utilisateur peut trouver un projet en utilisant un même nom de fichier universel au lieu d'avoir à se soucier de l'endroit ou il est stocké, a souligné le dirigeant. « Ainsi, une fois la politique établie, des fichiers peuvent être automatiquement déplacés d'un fuseau horaire à un autre. Lorsque la journée de travail se termine à Hollywood, des données primaires peuvent être déplacées vers un espace de stockage local et plus rapide à Singapour, où une autre équipe vient de commencer sa journée », a indiqué le CEO. Et à l'inverse, la datalocalisation des données est également possible pour répondre à des cadres juridiques spécifiques. Interrogé sur cette nouvelle aventure, Lance Smith a simplement avoué que l'idée de Primary Data avait commencé à germer chez Fusion-io.
Primary Data, la virtualisation pour simplifier le stockage
0
Réaction
Fondée par l'ancienne équipe de Fusion-io, Primary Data propose de gérer toutes les capacités de stockage d'une entreprise au sein d'un seul pool virtuel.
")
Newsletter LMI
Recevez notre newsletter comme plus de 50000 abonnés
Commentaire